



Chatbots answer user questions, whereas truly transformative AI systems can operate independently of human input. Since late 2022, we've deployed AI agents with our customers to autonomously analyze customer feedback, handle complex sales proposals, and conduct multi-source research—evolving from experimental prototypes to production-grade tools today. These systems represent the frontier of what the industry now calls "agentic AI."
Whether you're a seasoned AI engineer or new to the field, you'll find here hard-learned lessons that will save you time and headache as we cover the four essential components for building effective agents:
- clear instructions,
- well-designed tools,
- efficient memory management, and
- appropriate LLM selection.
This blog post is part 2 of our 3-part series on agentic AI. While part 1, “How to 3-4x Your ROI with AI Agents?”, focused on business value and use cases, this more technical writeup provides practical insights from our development experience. The final part will explore multi-agent collaboration patterns and things to consider with production-grade AI agents.
What is an AI Agent?
In traditional generative AI applications, interactions follow a simple back-and-forth pattern: the user requests information or assistance, a large language model (LLM) – the AI – responds, and the cycle repeats. These chatbots and copilots are useful, but they operate primarily as conversational partners rather than autonomous problem-solvers.
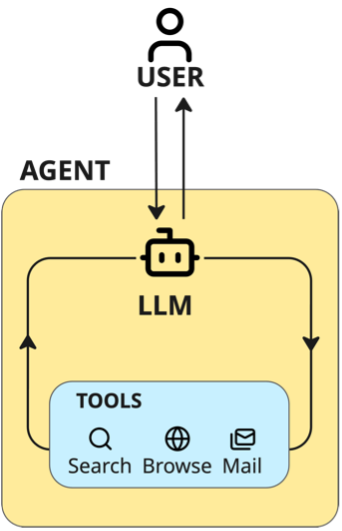
Agentic AI systems transform LLMs from passive responders into independent actors through three key properties:
- Goal orientation: The LLM receives explicit objectives and instructions that drive sustained, purposeful action
- Tool integration: A tool is simply a function which we execute for the LLM. For example, tools might query databases, fetch web content, send emails, or perform calculations. This allows the LLM to go beyond text generation and accomplish practical tasks.
- Execution orchestration: A loop that orchestrates this all allows the LLM to plan, call tools, reflect, and adapt until goals are achieved
It's really this simple. An AI Agent consists of just three components – an LLM, a set of tools for it to call, and a loop with simple orchestration logic. What makes this approach different from traditional software architecture is that the control flow is determined by the LLM itself. It decides what to do next: call tools, analyze data, or respond to back to the caller.
The following Python snippet demonstrates this simple pattern:
- Feed the agent’s current state to the LLM (instructions, user messages, previous LLM responses, and tool executions and results)
- Process the LLM’s output:
- Store the response in memory
- If the LLM called tools, execute them and add results to memory
- Determine next steps:
- If no tools were called, return the results and end the loop
- If tools were called, continue the loop with the updated state
The basic loop shown above is straightforward, but building robust, production-ready agents requires careful design. In practice, you'll quickly encounter challenges—agents calling the wrong tools, losing track of context, or becoming overwhelmed by complexity. Over time, we’ve found ourselves relying on the following design principles to consistently build agents that perform exceptionally well in real-world scenarios.
Anatomy of an Effective Agent
1. Clear Scope & Instructions
Today’s LLMs can perform well as generalists, but for agentic use cases, where the agent should execute its tasks independently, you’ll want to narrow down the scope and make it clear in the agent's instructions from the start. This is key to implementing highly efficient and performant agents.
We learned this lesson firsthand when working on a text analysis agent. Initially, we simply instructed it to "Provide key insights from the text.” The results were inconsistent and often surprising. What we had missed was clarifying several critical aspects:
- Task context: "The text you’ll receive is from ****. For these tasks, particularly important themes are ****, ****, and ****."
- Judgment criteria: Should the agent focus only on those themes? Should it try to infer the undertones in the text or only those themes that are explicitly present?
- Purpose: What is the downstream use of these insights?
- Format: Should the agent provide a long analysis, a summary, a JSON object? Include the reasoning for its insights or only the insights?
The model-dependence of our results was particularly revealing. When switching between different LLMs, we had to adjust our prompting to maintain consistent analysis. This highlights how much interpretation was happening behind the scenes with our vague instructions.
After refining our instructions to address these gaps, the agent’s consistency improved dramatically across both different text samples and different underlying LLMs.
Key insight: When designing agent instructions, explicitly state not just the task, but the context, success criteria, and constraints. What seems obvious to you as the developer may not be obvious to the LLM.
2. Well-Designed Tools
Together with the instructions, the tools you provide define the agent’s capabilities and limitations. We've found that thoughtful tool design is often the difference between an agent that struggles with basic tasks and one that excels at complex workflows.
Early on when we were developing a proof-of-concept of a business intelligence multi-agent we encountered significant challenges. Our data was sitting behind a complex API—essentially a REST API with deeply nested JSON schema—with separate APIs for setting filters on the database queries. We provided the LLM full read-access to the database API and a sandboxed Python playground where the agent could execute scripts to analyze the data.
This approach proved disastrous. Given unlimited capabilities with the database API and unlimited analysis options in the Python playground, the agent had too much leeway with data it didn't fully understand. The tools were simply too open-ended.
We solved this by implementing a restricted set of datasets to fetch ("KPIs – markets – segments – products..."), and a specific set of analysis operations it could execute (pivot, aggregation, filter, sum, avg...). This provided much-needed clarity for the LLM, transforming our confused AI into a BI master that could handle typical analyses that users requested.
While this example highlights LLMs' historical limitations (this was way before LLMs had native tool calling capabilities)., today's models have advanced significantly—our agents can now work with full SQL and database access. Nevertheless, the core principles of tool design remain crucial:
Keep tools stateless and focused. Rather than one complex "search_database" tool with many optional parameters, create separate tools for different query types. For example, when building a customer support agent, replace a generic "get_customer_data" function with specific tools like "get_customer_subscription", "get_recent_orders", and "get_support_history".
Design for LLM comprehension, not just functionality. The way tools return results significantly impacts the agent's ability to use them effectively. For example, in a document search functionality, if you just return the found paragraphs without any context on the rest of the document, the LLM is unlikely to understand it fully – or, in the worst case, fill the gaps with hallucinated content not based on the source data.
Build robust error handling into every tool. Since tools are the main way LLMs interact with external systems, they must be exceptionally reliable. Implement proper retries for API calls, handle edge cases carefully, and fallback gracefully when external services fail. Remember that the LLM will need to interpret any error messages, so make them clear and actionable.
Provide relevant information without overwhelming. While LLMs are increasingly capable, they still struggle with finding needles in data haystacks. When designing tool outputs, focus on returning precisely what the agent needs rather than dumping large datasets. For example, for a browsing tool, you might want to pre-extract the relevant content from the web page instead of returning all the site’s content.
Keep the number of tools reasonable. While it's tempting to give your agent every capability imaginable, this quickly becomes counterproductive. In practice, we've found that a single LLM can comfortably handle around a dozen tools. Beyond this point, LLMs often start struggling—either selecting the wrong tool or repeatedly defaulting to familiar ones based on past usage. If your scenario genuinely requires more tools, it's probably time to consider a multi-agent setup, where each agent specializes in a specific domain. We'll dive deeper into this multi-agent approach in the final part of this blog series.
Keep an eye on emerging standards. Right now, developing tools for agents often involves custom implementations and integrations. The Model Context Protocol (MCP) is one promising effort to standardize how AI systems discover and use tools, regardless of the underlying model or even the AI system itself. While MCP and similar standards are still evolving, adopting them early could simplify future integrations and help avoid vendor lock-in. It's worth tracking these developments—they signal an important shift toward more interoperable and flexible agentic AI systems.
Key insight: Despite advances in LLM capabilities, constraints often lead to better performing AI agents than unlimited freedom. Design tools that guide toward successful paths rather than leaving it to navigate complex possibilities independently.
3. Memory Management
As your agent executes tasks, it needs to remember relevant information from the previous steps. You’ll be storing instructions, user messages, tool calls, tool call results, and LLM’s internal messages/reflections and its messages back to the user in the memory. The simplest approach is to just pass the entire history back to the LLM on each call, but this will quickly run into limits in the amount of input the LLM can ingest. Effective memory management is about selecting what to keep and how to structure it.

In our simple snippet, memory management would correspond to adjusting the line:
to something like
where extract_relevant_memories will do the memory management for us.
When we built our first document analysis agent, we naively included the entire document in the input for each iteration. This worked for small documents but failed catastrophically when processing larger ones. The agent’s memory contents would reach the LLM input limits, making the analysis impossible.
We've since developed several patterns for agent memory management to solve these issues:
- Working memory vs. long-term memory: Working memory should always be in the LLM’s context. It contains the most recent user messages, internal reflections, and tool operations, and in addition, the immediate task at hand, and the core instructions of the agent. Long-term memory, on the other hand, stores, e.g., the entire history of the interaction, but is not fully injected into the input for LLM calls. For agents that run dozens or hundreds of turns, you’ll notice this distinction becomes helpful—you can't keep everything in the context forever.
- Context memory (RAG pattern): Unlike working and long-term memory which store interaction history, context memory retrieves relevant information from external knowledge bases. When your agent needs domain-specific knowledge, you can query a database to pull in only the most relevant documents or passages to the current task and inject them in the LLM’s memory. This allows agents to work with knowledge far beyond what could fit in their working memory, accessing precisely what's needed when it's needed.
- Resurface important memories from the long-term memory: You might wish to summarize the long-term memory or only resurface relevant sections of it. For example, consider a document agent, where the agent is used to extract and summarize key information about sets of documents. We might eventually want to implement, e.g., a quality control step to double check the LLM-generated synthesis. However, after quality has been verified, there’s no reason to further feed those steps back in any succeeding LLM calls.
- Hierarchy of memory stores: Often you’ll want to implement a hierarchy of long-term and context memory stores. A session memory for the current agent run, a user-memory for keeping user-specific insights and guidance, and a company-memory for storing overall instructions, documents, guidelines and whatnot. This will allow you to operate on different levels when deciding how to include relevant information for the LLM calls.
There are two final learnings from LLM memory management we’d like to share with you. First, what context, memories, you provide for the LLM will affect how it operates. This is true even when the memories are irrelevant for the task at hand. If you provide a list of your company services for the LLM when it analyzes requests for proposal, this will guide it to see the RFP from your company services point of view. This might be a good thing, for the agent gets more understanding of the context for the RFP, but this might be a bad thing if your initial goal was to filter out RFPs that are not relevant for your business.
Second, we’ve noticed that with long message histories, some LLMs start going off tangents from the core task. Long-term session memory, only part of which is in the active context, will help to some extent, but what seems to really help is resurfacing the core task as a reminder near the end of the context window, helping the LLM keep its focus.
Key Insight: Agent memory isn’t about storing everything. You need to develop ways to decide what to keep immediately accessible versus what to resurface only when needed, and what information is relevant for the agent’s current state.
4. LLM Selection
Your first instinct might be to use the latest flagship model, and stakeholders often request this too. While powerful LLMs are sometimes necessary for agentic AI, we've learned to balance capabilities with task complexity, speed, and cost.
In essence, you need to select the LLM by matching model capabilities with the task complexity:
- Small and fast models (like Claude Haiku, Gemini Flash-Lite, and GPT-4o-mini) excel at basic pattern recognition and classification. These work well for easy tasks such as sentiment and emotion analysis and extracting structured data from documents.
- Mid-tier models (Claude Sonnet, Gemini Flash, GPT-4o) handle moderate reasoning and tool usage with reasonable latency. These are ideal for, e.g., web browsing agents, multi-step workflows, and routine customer support.
- Top-tier models (Claude Sonnet 3.7R, Gemini Flash Thinking, O1/O3-mini) are necessary for complex, open-ended problem solving. Their reasoning capabilities make them suitable for, e.g., research synthesis and document generation for sales proposals.
For narrow-domain tasks, we've also seen remarkable results with fine-tuned smaller models. For example, in thematic analysis we found fine-tuned GPT-4o-mini not only outperformed GPT-4o in quality but also delivered significantly higher throughput.
Key Insight: The best model isn't always the most powerful one. Evaluate your requirements across complexity, speed, and cost dimensions rather than defaulting to the latest flagship model.
Bringing It All Together
Building effective AI agents isn't about chasing the latest frameworks or most powerful models. The core idea is really simple: a loop for (1) an API call to an LLM, (2) handling of calling external tools for the LLM, and (3) terminating the loop based on some conditions.
You need four key components to succeed:
- Clear instructions that define scope and success criteria for the AI agent,
- Well-designed tools that the agent understands how to use,
- Memory management that maintains relevant context without overwhelming the LLM, and
- The right LLM selected based on task complexity.
We’ll conclude this blog series soon with a final part. We'll share learnings from building production-grade agentic AI: how to make multiple agents work together, what the system architecture looks like when you scale beyond proofs of concept, and some lessons about picking the right frameworks for your build.
Stay tuned!


.jpg)
